


8. Chaînes▲
Les chaînes sont des entités différentes des entiers, des flottants et des booléens. Elles font partie des structures de données (comme les tableaux [chapitre 10Tableaux], les dictionnaires [chapitre 11Dictionnaires], les tuples [chapitre 12Tuples] et les structures composites [chapitre 16Structures et fonctions et suivants]). Une chaîne est une séquence, ce qui signifie qu'elle forme un ensemble ordonné de valeurs. Dans ce chapitre, nous voyons comment accéder aux caractères qui composent une chaîne et nous découvrirons certaines fonctions d'aide fournies par Julia afin de manipuler des chaînes.
8-1. Caractères▲
Les locuteurs de langue anglaise sont familiarisés avec les caractères tels que les lettres de l'alphabet (A, B, C…), les chiffres et la ponctuation courante. Ces caractères sont normalisés et mis en correspondance avec des valeurs entières comprises entre 0 et 127 par la norme ASCII (American Standard Code for Information Interchange).
Il existe bien sûr de nombreux autres caractères utilisés dans d'autres langues que l'anglais, y compris des variantes des caractères ASCII avec des accents et d'autres modifications, des écritures connexes telles que le cyrillique et le grec, et des écritures sans aucun rapport avec l'ASCII et l'anglais, notamment l'arabe, le chinois, l'hébreu, l'hindi, le japonais et le coréen.
La norme Unicode traite les difficultés associées à la définition exacte d'un caractère et elle est généralement acceptée comme la norme définitive pour résoudre ces problèmes. Elle fournit un numéro unique pour chaque caractère à l'échelle mondiale.
Une valeur Char représente un seul caractère et elle est entourée de guillemets droits simples :
2.
3.
4.
5.
6.
julia> 'x'
'x': ASCII/Unicode U+0078 (category Ll: Letter, lowercase)
julia> '🍌'
'🍌': Unicode U+1F34C (category So: Symbol, other)
julia> typeof('x')
Char
Même les emojis(15) font partie de la norme Unicode (par exemple, \:banana: TAB)
8-2. Une chaîne est une séquence▲
Une chaîne est une séquence de caractères. Il nous est loisible d'accéder aux caractères un à un avec l'opérateur crochets appairés [ ] :
2.
3.
4.
julia> fruits = "banane"
"banane"
julia> letter = fruit[1]
'b': ASCII/Unicode U+0062 (category Ll: Letter, lowercase)
La deuxième déclaration sélectionne le caractère numéro 1 de la variable fruit et l'attribue à la variable letter.
L'expression entre parenthèses contient un indice qui désigne le caractère traité de la séquence.
En Julia, toute séquence indicée commence à 1 : le premier élément de tout objet indicé sur la base de nombres entiers se trouve à l'indice 1 et le dernier élément correspond à end (voir la figure 8.2.1).
|
|
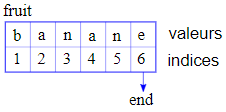
Par exemple,
2.
julia> fruit[end]
'e': ASCII/Unicode U+0065 (category Ll: Letter, lowercase)
Comme pour tout indice, une expression qui contient des variables et des opérateurs peut être employée :
2.
3.
4.
5.
6.
julia> i = 1
1
julia> fruit[i+1]
'a': ASCII/Unicode U+0061 (category Ll: Letter, lowercase)
julia> fruit[end-1]
'n': ASCII/Unicode U+006E (category Ll: Letter, lowercase)
Naturellement, la valeur d'un indice doit être un entier, à défaut de quoi Julia retourne une erreur :
2.
julia> fruit[1.5]
ERROR: MethodError: no method matching getindex(::String, ::Float64)
8-3. length▲
length est une fonction interne qui retourne le nombre de caractères d'une chaîne :
2.
3.
4.
julia> fruits = "🍌 🍎 🍐"
"🍌 🍎 🍐"
julia> len = length(fruits)
5
Pour obtenir la dernière lettre d'une chaîne, il est tentant d'essayer ceci :
2.
julia> last = fruits[len]
'': ASCII/Unicode U+0020 (category Zs: Separator, space)
Le résultat est quelque peu inattendu. Les chaînes sont encodées en utilisant le codage UTF-8. Or, l'UTF-8 est un codage à largeur variable, ce qui signifie que tous les caractères ne sont pas codés avec le même nombre d'octets.
La fonction sizeof retourne le nombre d'octets d'une chaîne :
2.
julia> sizeof("🍌")
4
Étant donné qu'un pictogramme est codé sur 4 octets et que l'indexation des chaînes est basée sur les octets, le 5e élément de fruits est un ESPACE. Cela signifie également que l'indice de chaque octet dans une chaîne UTF-8 n'est pas nécessairement l'indice valide pour un caractère. Si un tel indice d'octet non valide était utilisé dans une chaîne, Julia afficherait une erreur :
2.
julia> fruits[2]
ERROR: StringIndexError("🍌 🍎 🍐", 2)
Dans le cas de fruits, le pictogramme 🍌 s'étend sur quatre octets. Les indices 2, 3 et 4 ne sont donc pas valables et l'indice du caractère suivant est 5. Cet indice valable suivant peut être calculé par nextind(fruits, 1). L'indice suivant peut être obtenu par nextind(fruits, 5) et ainsi de suite.
8-4. Parcours d'une chaîne▲
De nombreux programmes requièrent le traitement en série d'une ou plusieurs chaînes de caractères. Souvent, ces traitements commencent au tout début. Ils sélectionnent chaque caractère à tour de rôle, effectuent une ou plusieurs modifications puis continuent jusqu'à la fin de la chaîne. Ce type de traitement correspond à une traversée ou un parcours de chaîne. Une façon d'effectuer un tel traitement consiste à recourir à une boucle while :
2.
3.
4.
5.
6.
index = firstindex(fruits)
while index <= sizeof(fruits)
letter = fruits[index]
println(letter)
global index = nextind(fruits, index)
end
Cette boucle parcourt la chaîne et affiche chaque élément ligne après ligne. La condition de la boucle est index <= sizeof(fruits). Donc, quand l'indice est plus grand que le nombre d'octets dans la chaîne, la condition devient fausse et le corps de la boucle n'est plus exécuté.
La fonction firstindex retourne le premier indice d'octet valide. Le mot-clé global précédant index indique que nous voulons réaffecter l'indice de la variable définie dans Main (voir la section 11.7Variables globales).
8-4-1. Exercice 8-1▲
Écrivez une fonction qui prend une chaîne de caractères comme argument et affiche les lettres à l'envers, une par ligne.
La lecture intégrale d'une chaîne peut être menée à bien avec une boucle for :
2.
3.
for letter in fruits
println(letter)
end
À chaque passage dans la boucle, le caractère suivant de la chaîne est attribué à la variable letter. La boucle se poursuit jusqu'à ce qu'il n'y ait plus de caractère à lire.
L'exemple suivant montre l'utilisation de la concaténation (mise bout à bout de plusieurs chaînes de caractères) et d'une boucle for pour produire une série alphabétiquement ordonnée. Dans le célèbre livre américain pour enfants de Robert McCloskey intitulé Make Way for Ducklings (dont la traduction en français a pour titre Laissez passer les canards), les noms des canetons sont Jack, Kack, Lack, Mack, Nack, Ouack, Pack et Quack. La boucle for ci-dessous produit ces noms dans l'ordre :
2.
3.
4.
5.
prefixes = "JKLMNOPQ"
suffix = "ack"
for letter in prefixes
println(letter * suffix)
end
Le programme retourne :
2.
3.
4.
5.
6.
7.
8.
Jack
Kack
Lack
Mack
Nack
Oack
Pack
Qack
Ce retour est toutefois incorrect, puisque Ouack et Quack ne sont pas correctement écrits.
8-4-2. Exercice 8-2▲
Modifiez le programme précédent pour corriger cette erreur.
8-5. Segments de chaînes▲
Un segment de chaîne est appelé slice en anglais. La sélection d'un segment est similaire à la sélection d'un caractère :
2.
3.
4.
julia> str = "Jules César";
julia> str[1:5]
"Jules"
L'opérateur [n:m] retourne la partie de la chaîne du nième au mième octet. Il faut donc faire preuve de la même prudence que pour lors de la manipulation d'indices simples.
Le mot-clé end peut être utilisé pour indiquer le dernier octet de la chaîne :
2.
julia> str[7:end]
"César"
Si le premier indice est supérieur au second, le résultat est une chaîne vide entourée de deux guillemets doubles :
2.
julia> str[78:7]
" "
Une chaîne vide ne contient aucun caractère et a une longueur égale à 0. Mis à part cela, ses caractéristiques sont identiques à toute autre chaîne.
8-5-1. Exercice 8-3▲
Pour poursuivre cet exemple, que pensez-vous que str[:] signifie ? Essayez.
8-6. Les chaînes sont persistantes▲
Il est tentant d'utiliser l'opérateur [ ] sur le côté gauche d'une affectation, avec l'intention de changer un caractère dans une chaîne. Par exemple :
2.
3.
4.
julia> salut = "Hello, world!"
"Hello, world!"
julia> salut[1] = 'J'
ERROR: MethodError: no method matching setindex!(::String, ::Char, ::Int64)
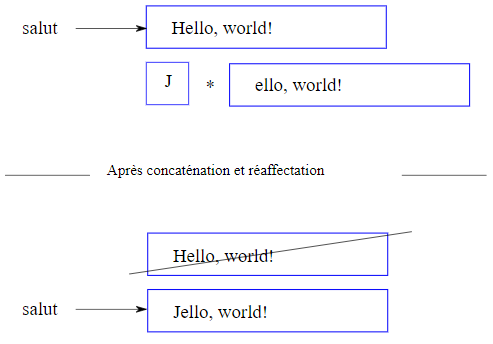
La raison de cette erreur provient de ce que les chaînes de caractères sont persistantes ou inchangeables (immutable en anglais). Cela signifie qu'une chaîne existante ne peut pas être modifiée. Le mieux qu'on puisse faire est de créer une nouvelle chaîne qui soit une variation de l'originale :
2.
julia> salut = J * salut[2:end]
"Jello, world!"
Cet exemple concatène une nouvelle première lettre avec un segment de salut. Il n'a aucun effet sur la chaîne de caractères originale. Ceci est explicité dans la figure 8.6.1.
|
|
8-7. Interpolation des chaînes▲
Construire des chaînes de caractères en utilisant la concaténation peut devenir rapidement ardu. Pour réduire la nécessité de ces appels verbeux à string ou à des multiplications de chaîne, Julia autorise l'interpolation de chaînes à l'aide de $ :
2.
3.
4.
5.
6.
julia> salut1 = "Hello"
"Hello!"
julia> a_qui = "World"
"World"
julia> "$salut1, $(a_qui)!"
"Hello, World!"
Cette formulation est plus lisible et plus pratique que la concaténation de chaînes : salut1 * ", " * a_qui * "!".
L'expression complète la plus courte après le $ est prise comme l'expression dont la valeur doit être interpolée. Ainsi, toute expression dans une chaîne peut être interpolée en utilisant des parenthèses(16) :
2.
julia> greet = "1 + 2 = $(1 + 2)"
"1 + 2 = 3"
8-8. Recherche dans les chaînes▲
Que fait la fonction suivante ?
2.
3.
4.
5.
6.
7.
8.
9.
10.
function find(word, letter)
index = firstindex(word)
while index <= sizeof(word)
if word[index] == letter
return index
end
index = nextind(word, index)
end
-1
end
Dans un sens, cette fonction find est l'inverse de l'opérateur [ ]. Au lieu de prendre un indice et d'extraire le caractère correspondant, elle prend un caractère et trouve l'indice où ce caractère apparaît. Si le caractère n'est pas trouvé, la fonction retourne -1.
C'est le premier exemple que nous voyons d'une déclaration de retour à l'intérieur d'une boucle. Si word[index] == letter, la fonction sort de la boucle et retourne immédiatement la position de la lettre.
Si le caractère n'apparaît pas dans la chaîne de caractères, le programme sort normalement de la boucle en retournant -1.
Ce schéma de calcul s'appelle une recherche.
8-8-1. Exercice 8-4▲
Modifiez find pour qu'elle contienne un troisième paramètre, en l'occurrence l'indice dans word où la recherche doit commencer.
8-9. Boucle et compteur▲
Le programme suivant compte le nombre d'occurrences de la lettre a dans une chaîne :
2.
3.
4.
5.
6.
7.
8.
word = "banane"
counter = 0
for letter in word
if letter == 'a'
global counter = counter + 1
end
end
println(counter)
Ce programme illustre un mode de calcul avec emploi d'un compteur. Le compteur est une variable initialisée à 0 puis incrémentée (+1) à chaque fois que la lettre a est détectée. Lorsque la boucle se termine, le compteur contient la somme des occurrences de a.
8-9-1. Exercice 8-5▲
Encapsulez le code précédent dans une fonction appelée count et généralisez-le pour qu'il accepte la chaîne et la lettre comme arguments.
Ensuite, réécrivez la fonction de sorte que, au lieu de parcourir la chaîne de caractères, count utilise la version à trois paramètres de find évoquée dans la section 8.8Recherche dans les chaînes.
8-10. Bibliothèque des chaînes▲
Julia fournit des fonctions qui permettent d'effectuer diverses opérations utiles sur les chaînes de caractères. Par exemple, la fonction uppercase prend une chaîne de caractères et retourne une nouvelle chaîne, toutes ses lettres étant converties en majuscules.
2.
julia> uppercase("Hello, World!")
"HELLO, WORLD!"
Il s'avère qu'il existe une fonction appelée findfirst qui est remarquablement similaire à la fonction find que nous avons écrite :
2.
julia> findfirst("a", "banane")
2:2
En fait, la fonction findfirst est plus générale que notre fonction find. En plus des caractères, elle peut trouver des sous-chaînes :
2.
julia> findfirst("ane", "banane")
4:6
Par défaut, findfirst commence au début de la chaîne de caractères, mais la fonction findnext prend un troisième argument, l'indice où elle doit commencer :
2.
julia> findnext("ne", "banane", 3)
5:6
8-11. L'opérateur ∈▲
L'opérateur ∈ (\in TAB) est un booléen(17) qui prend un caractère et une chaîne. Il retourne true si le caractère apparaît dans la chaîne :
2.
julia> 'a' ∈ "banane"
true
Par exemple, la fonction suivante permet d'afficher toutes les lettres de word1 qui apparaissent également dans word2 :
2.
3.
4.
5.
6.
7.
function inboth(word1, word2)
for letter in word1
if letter ∈ word2
print(letter, " ")
end
end
end
Avec des noms de variables bien choisis, Julia se lit parfois comme du français. Ainsi, cette boucle peut être lue comme ceci : « pour (chaque) lettre du (premier) mot, si (la) lettre est un élément du (deuxième) mot, affichez (ladite) lettre ». Voici ce qui se passe quand on « compare » des pommes et des poires.
2.
julia> inboth("pommes", "poires")
p o e s
8-12. Comparaison de chaînes▲
Les opérateurs relationnels fonctionnent aussi avec les chaînes. Pour voir si deux chaînes sont égales :
2.
3.
4.
word = "Prigogine"
if word == "thermodynamique"
println("Génial, la thermodynamique.")
end
D'autres opérations relationnelles sont utiles pour mettre les mots en ordre alphabétique :
2.
3.
4.
5.
6.
7.
8.
word = "Prigogine"
if word < "thermodynamique"
println("Le mot $word vient avant thermodynamique.")
elseif word > "thermodynamique"
println("Le mot $word vient après thermodynamique.")
else
println("Génial, la thermodynamique.")
end
Julia ne gère pas les lettres majuscules et minuscules comme nous le faisons. Toutes les lettres majuscules passent avant les minuscules, le résultat est donc :
Le mot Prigogine vient avant thermodynamique.
Une manière courante de résoudre ce problème consiste à convertir les chaînes de caractères en un format standard, par exemple toutes les minuscules, avant d'effectuer la comparaison.
8-13. Débogage▲
Lorsque des indices sont exploités pour parcourir les valeurs d'une chaîne séquentiellement, il est délicat d'obtenir le début et la fin exacts de la traversée de chaîne. Voici une fonction qui est censée comparer deux mots et retourner true si l'un des mots est l'inverse de l'autre. Cependant, elle contient deux erreurs :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
function isreverse(word1, word2)
if length(word1) != length(word2)
return false
end
i = firstindex(word1)
j = lastindex(word2)
while j >= 0
j = prevind(word2, j)
if word1[i] != word2[j]
return false
end
i = nextind(word1, i)
end
true
end
La première déclaration vérifie si les mots sont de la même longueur. Si ce n'est pas le cas, nous pouvons immédiatement retourner false. Sinon, pour le reste de la fonction, nous supposons que les mots sont de la même longueur. C'est un exemple avec une sentinelle.
i et j sont des indices : i parcourt word1 vers l'avant tandis que j parcourt word2 à rebours. Si nous trouvons deux lettres qui ne correspondent pas, nous pouvons retourner false immédiatement. Si toute la boucle est parcourue et que toutes les lettres correspondent, le programme retourne true.
La fonction lastindex retourne le dernier indice d'octet valide de la chaîne de caractères et prevind l'indice valide du caractère précédent.
Si nous testons cette fonction avec les mots « pots » et « stop », nous nous attendons à ce que la valeur de retour soit true. Ce n'est pourtant pas le cas :
2.
julia> isreverse("pots", "stop")
false
Pour déboguer ce genre d'erreur, la première démarche consiste à imprimer la valeur des indices dans la séquence :
2.
3.
4.
while j >= 0
j = prevind(word2, j)
@show i j
if word1[i] != word2[j]
En relançant le programme, nous obtenons de précieuses informations :
2.
3.
4.
julia> isreverse("pots", "stop")
i = 1
j = 3
false
Lors du premier passage dans la boucle, j vaut 3. Or, ce devrait être 4. Cette valeur peut être fixée en déplaçant la ligne j = prevind(word2, j) à la fin de la boucle while.
Cela accompli, le programme est relancé, ce qui conduit au résultat :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
julia> isreverse("pots", "stop")
i = 1
j = 4
i = 2
j = 3
i = 3
j = 2
i = 4
j = 1
i = 5
j = 0
ERROR: BoundsError: attempt to access "pots" at index [5]
Cette fois, une BoundsError a été émise. La valeur de i est de 5, ce qui est en dehors de la plage pour la chaîne « pots ».
8-13-1. Exercice 8-6▲
Exécutez le programme sur papier, en changeant les valeurs de i et j à chaque itération. Trouvez et corrigez la deuxième erreur dans cette fonction.
8-14. Glossaire▲
séquence collection ordonnée de valeurs où chaque valeur est identifiée par un indice entier,
norme ASCII norme de codage des caractères pour la communication électronique spécifiant 128 caractères,
norme Unicode norme de l'industrie informatique pour le codage, la représentation et le traitement cohérents des textes exprimés dans la plupart des systèmes d'écriture du monde,
indice valeur entière utilisée pour sélectionner un élément dans une séquence, tel qu'un caractère dans une chaîne de caractères. En Julia, les indices commencent à 1,
encodage UTF-8 encodage de caractères à largeur variable capable de coder tous les 1112064 points de code valides en Unicode en utilisant un à quatre octets de 8 bits (abréviation de l'anglais Universal Character Set Transformation Format – 8 bits),
traversée lecture des éléments dans une séquence, en effectuant une opération similaire sur chacun d'eux,
segment (slice) partie d'une chaîne de caractères délimitée par une série d'indices,
chaîne vide chaîne sans caractères et de longueur 0, représentée par deux guillemets droits,
persistance (ou immutability) propriété d'une séquence dont les éléments ne peuvent pas être modifiés,
interpolation de chaîne processus d'évaluation d'une chaîne contenant un ou plusieurs caractères, donnant un résultat dans lequel les caractères sont remplacés par leurs valeurs correspondantes,
recherche modèle de traversée d'une séquence qui s'arrête lorsqu'il trouve ce qu'il cherche,
compteur variable généralement initialisée à zéro puis incrémentée d'une unité à chaque passage dans une boucle.
8-15. Exercices▲
8-15-1. Exercice 8-7▲
Le but de cet exercice est de consulter la documentation Julia associées aux chaînes. Vous voudrez peut-être essayer certaines fonctions pour vous assurer que vous comprenez leur fonctionnement. Les méthodes strip et replace sont particulièrement utiles.
La documentation utilise une syntaxe qui peut être déroutante. Par exemple, dans search(string::AbstractString, chars::Chars, [start::Integer]), les crochets indiquent des arguments optionnels. Ainsi, string et chars sont obligatoires, tandis que start est optionnel.
8-15-2. Exercice 8-8▲
Il existe une fonction interne appelée count similaire à la fonction count de la section 8.9Boucle et compteur (voir en particulier l'exercice 8.9.1Exercice 8-5 et la section 4.9Documentation interne). Lisez la documentation de count et utilisez-la pour compter le nombre de a dans « abracadabra ».
8-15-3. Exercice 8-9▲
Un segment de chaîne peut prendre un troisième indice. Le premier indique le début, le troisième la fin et le deuxième la « taille du pas », c'est-à-dire le nombre d'espaces entre les caractères successifs. Un pas de 2 signifie un caractère sur deux, un pas de 3 signifie un caractère sur trois, etc.
2.
3.
4.
julia> mot = "servovalve"
"servovalve"
julia> mot[1:2:6]
"sro"
Un pas de -1 traverse le mot à l'envers, de sorte que [end:-1:1] produit une chaîne inversée. Utilisez cette technique pour écrire une version d'une ligne de la fonction ispalindrome (exercice de la sous-section 6.11.3Exercice 6-6).
8-15-4. Exercice 8-10▲
Les fonctions suivantes sont toutes destinées à vérifier si une chaîne de caractères contient des minuscules, mais certaines d'entre elles sont erronées. Pour chaque fonction, décrivez ce que la fonction fait réellement (en supposant que le paramètre est une chaîne de caractères).
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
function anylowercase1(s)
for c in s
if islowercase(c)
return true
else
return false
end
end
end
function anylowercase2(s)
for c in s
if islowercase('c')
return "true"
else
return "false"
end
end
end
function anylowercase3(s)
for c in s
flag = islowercase(c)
end
flag
end
function anylowercase4(s)
flag = false
for c in s
flag = flag || islowercase(c)
end
flag
end
function anylowercase5(s)
for c in s
if !islowercase(c)
return false
end
end
true
end
8-15-5. Exercice 8-11▲
Un code César est une forme de chiffrement faible qui implique le décalage de chaque lettre par un nombre fixe (le cas échéant, une lettre peut revenir à sa place initiale). Par exemple, 'A' décalé de 3 devient 'D' et 'Z' décalé de 1 devient 'A'.
Pour faire pivoter un mot, il suffit de décaler chaque lettre de la même manière. Par exemple, « oui » décalé de 10 devient « yes » et « lit » décalé de 7 devient « spa », et décalé de -4 devient « hep ». Dans le film 2001 : l'Odyssée de l'espace, l'ordinateur du vaisseau s'appelle HAL, c'est-à-dire IBM décalé de -1.(18)
Écrivez une fonction appelée rotateword qui prend une chaîne de caractères ainsi qu'un entier comme paramètres et retourne une nouvelle chaîne de caractères contenant les lettres de la chaîne originale pivotée de la quantité donnée.
Vous pouvez utiliser la fonction intégrée Int, qui convertit un caractère en un code numérique, et Char, qui convertit les valeurs numériques en caractères. Les lettres de l'alphabet sont codées dans l'ordre alphabétique, par exemple :
2.
julia> Int('c') - (Int'a')
2
Cela parce que c est la troisième lettre de l'alphabet. Prudence : les codes numériques des lettres majuscules sont différents :
2.
julia> Char(Int('A') + 32)
'a': ASCII/Unicode U+0061 (category Ll: Letter, lowercase)
